R语言通常被认为是统计学家和数据科学家的语言. 很久以前,这几乎是真的. However, 多年来,R通过包提供的灵活性使R成为一种更通用的语言. R在1995年开源,从那时起 R包的存储库在不断增长. 尽管如此,与Python等语言相比,R还是强烈地基于数据.
说到数据, 表格数据值得特别注意, 因为它是最常用的数据类型之一. 它是一种数据类型,对应于数据库中已知的表结构, 每一列可以是不同的类型, 对于许多应用程序来说,特定数据类型的处理性能是至关重要的因素.

在本文中, 我们将介绍如何以一种有效的方式实现表格数据转换. Many 使用R的人 已经对机器学习没有意识到这一点 数据绿豆 可以在R中更快地完成,并且他们不需要使用其他工具.
以R为底引入了 data.frame 类,它是基于之前的S-PLUS. 与常用的逐行存储数据的数据库不同,R data.frame 将数据作为面向列的结构存储在内存中, 因此,对于分析中常见的列操作,它的缓存效率更高. 另外, 尽管R是一种函数式编程语言, 它不会对开发人员强制执行. 中国很好地把握了这两个机遇 data.table R包,可在CRAN存储库中获得. 它在分组操作时执行得相当快, 并且通过小心地具体化中间数据子集来提高内存效率, 例如,只具体化某个任务所需的那些列. 在添加或更新列时,它还通过引用语义避免了不必要的复制. 该软件包的第一个版本已于2006年4月发布,显著改进 data.frame 当时的表现. 最初的包描述是:
这个包做的很少. 它存在的唯一原因是白皮书指定了该数据.框架必须有行名. 这个包定义了一个新的类data.表,它的操作就像一个数据.帧,但使用最多10倍的内存,并可以高达10倍的速度来创建(和复制). 它还允许子集()和with()类似表达式在[]中. 大多数代码都是从基函数中复制的,其中包含代码操作行.名字删除.
从那以后, data.frame and data.table 实现已经得到了改进,但是 data.table 仍然比以R为底的速度快得多. In fact, data.table 不仅比以R为底的快, 但它似乎是可用的最快的开源数据争论工具之一, 与诸如 Python熊猫,以及列式存储数据库或大数据应用程序,如 Spark. 它在分布式共享基础设施上的性能还没有进行基准测试, 但是能够在单个实例上拥有多达20亿行,这给了我们很大的希望. 出色的表现与成功携手并进 功能. 另外, 最近在并行化耗时部分以获得增量性能方面的努力, 推动性能极限的一个方向似乎相当明确.
学习R变得简单了一点,因为它是交互式的, 因此,我们可以一步一步地遵循示例,并随时查看每一步的结果. 在开始之前,让我们安装 data.table 包从CRAN存储库.
install.包(“数据.table")
有用的提示:我们可以打开任何一个函数的使用手册,只要输入它的名字加上前面的问号i.e. ?install.packages.
有大量的软件包用于从各种格式和数据库中提取数据, 通常包括本地驱动程序. 中加载数据 CSV 文件,原始表格数据最常用的格式. 可以找到以下示例中使用的文件 here. 我们不必为此烦恼 CSV 阅读性能 fread 函数在此基础上进行了高度优化.
为了使用包中的任何函数,我们需要用 library call.
库(数据.table)
DT <- fread("flights14.csv")
print(DT)
##年月日dep_delay arr_delay载波原点dest air_time
## 1: 2014 1 1 14 13 aa肯尼迪国际机场359
## 2: 2014年1 1 -3 13 aa肯尼迪国际机场363
## 3: 2014年1 1 2 9 aa肯尼迪国际机场351
## 4: 2014 1 1 -8 -26 aa lga pbi 157
## 5: 2014年1 1 2 1 aa肯尼迪机场lax 350
## ---
## 253312: 2014年10月31日1 -30日
## 253313: 2014年10月31日-5日-14日
## 253314: 2014 10 31 -8 16 mq lga rdu 83
## 253315: 2014 10 31 -4 15 mq lga DTW 75
## 253316: 2014 10 31 -5 1 mq lga SDF 110
##距离小时
## 1: 2475 9
## 2: 2475 11
## 3: 2475 19
## 4: 1035 7
## 5: 2475 13
## ---
## 253312: 1416 14
## 253313: 1400 8
## 253314: 431 11
## 253315: 502 11
## 253316: 659 8
如果我们的数据没有很好地建模以进行进一步处理, 因为它们需要从长到宽或从宽到长(也称为 pivot and unpivot)格式,我们可以看看 ?dcast and ?melt 函数,从 reshape2 package. However, data.table 为数据实现更快和内存效率更高的方法.表/数据.框架类.
data.table Syntaxdata.frame
Query data.table 很像查询吗 data.frame. 在进行过滤时 i 参数时,可以直接使用列名,而不需要使用 $ 标志,就像 df[df$col > 1, ]. 提供下一个参数时 j的作用域内提供要求值的表达式 data.table. 传递一个非表达式 j 参数使用 与= FALSE. 第三个参数,不在 data.frame 方法,定义组,使表达式在 j 分组评估.
# data.frame
DF[DF$col1 > 1L, c("col2", "col3")]
# data.table
DT[col1 > 1L, .(col3 col2), ...使用:' by = col4 '
Query data.table 在许多方面对应于更多人可能熟悉的SQL查询. DT 下面的代表 data.table 对象,并与sql相对应 FROM clause.
DT[i =其中,
J = select | update
[组]
[ having, ... ]
命令; ... ]
[ ... ] ... [ ... ]

对数据进行排序是时间序列的一个关键转换, 它还用于数据提取和表示. 排序可以通过提供行顺序为的整数向量来实现 i 论证,和 data.frame. 查询中的第一个参数 订单(载体,-dep_delay) 是否按升序选择数据 carrier 字段和降序排列 dep_delay measure. 第二个参数 j, 如前一节所述, 定义要返回的列(或表达式)及其顺序.
ans <- DT[订单(载体,-dep_delay),
.(载波,原点,dest, dep_delay)]
head(ans)
##载波原点dest dep_delay
## 1: aa ewr DFW 1498
## 2:肯尼迪机场1241号
## 3: aa ewr DFW 1071
## 4: a ewr DFW 1056
## 5: aa ewr DFW 1022
## 6: a ewr DFW 989
为了通过引用重新排序数据,而不是按特定顺序查询数据,我们使用 set* functions.
setorder(DT, carrier, -dep_delay)
leading.cols <- c("carrier","dep_delay")
setcolorder (DT, c(领先.cols, setdiff(names(DT), leading.cols)))
print(DT)
##运营商dep_delay年月日arr_delay原点dest air_time
## 1: aa 1498 2014 10 4 1494 ewr DFW 200
## 2: aa 1241 2014 4 15 1223 JFK bos 39
## 3: aa 1071 2014 6 13 1064 ewr DFW 175
## 4: aa 1056 2014 9 12 1115 ewr DFW 198
## 5: aa 1022 2014 6 16 1073 ewr DFW 178
## ---
## 253312: wn -12 2014 3 9 -21 lga bna 115
## 253313: wn -13 2014 3 10 -18 ewr MDW 112
## 253314: wn -13 2014 5 17 -30 lga hou 202
## 253315: wn -13 2014 6 15 10 lga mke 101
## 253316: wn -13 2014 8 19 -30 lga cak 63
##距离小时
## 1: 1372 7
## 2: 187 13
## 3: 1372 10
## 4: 1372 6
## 5: 1372 7
## ---
## 253312: 764 16
## 253313: 711 20
## 253314: 1428 17
## 253315: 738 20
## 253316: 397 16
大多数情况下,我们不需要 both 原始数据集和有序/排序数据集. 默认情况下, R语言, 类似于其他函数式编程语言, 将返回排序数据作为新对象, 因此需要的内存是引用排序的两倍.
让我们为航班起点“JFK”和月份从6到9创建一个子集数据集. 在第二个参数中,我们将结果子集到列出的列,并添加一个计算变量 sum_delay.
ans <- DT[origin == "JFK" & 月%在% 6:9,
.(origin, month, arr_delay, dep_delay, sum_delay = arr_delay + dep_delay)]
head(ans)
## origin month . array_delay . dep_delay . sum_delay
## 1: JFK 7 925 926 1851
## 2: JFK 8 727 772 1499
## 3: JFK 6 466 451 917
## 4: JFK 7 414 450 864
## 5: JFK 6 411 442 853
## 6: JFK 6 333 343 676
默认情况下,当将数据集子集设置为单列时 data.table 会自动为该列创建索引吗. 这导致 real-time 对该列的任何进一步过滤调用的回答.
按引用添加新列是使用 := 操作符,它将一个变量赋值到数据集中. 这避免了在内存中复制数据集,因此我们不需要将结果分配给每个新变量.
DT[, sum_delay:= arr_delay + dep_delay]
head(DT)
##运营商dep_delay年月日arr_delay原点dest air_time
## 1: aa 1498 2014 10 4 1494 ewr DFW 200
## 2: aa 1241 2014 4 15 1223 JFK bos 39
## 3: aa 1071 2014 6 13 1064 ewr DFW 175
## 4: aa 1056 2014 9 12 1115 ewr DFW 198
## 5: aa 1022 2014 6 16 1073 ewr DFW 178
## 6: aa 989 2014 6 11 991 ewr DFW 194
##距离小时sum_delay
## 1: 1372 7 2992
## 2: 187 13 2464
## 3: 1372 10 2135
## 4: 1372 6 2171
## 5: 1372 7 2095
## 6: 1372 11 1980
要一次添加更多变量,可以使用 DT[, :=(sum_delay = arr_delay + dep_delay)] 语法类似于 .(sum_delay = arr_delay + dep_delay) 从数据集查询时.
可以通过引用进行子分配, 只更新特定的行, 仅仅通过结合 i argument.
DT[起源= =“肯尼迪”,
距离:= NA]
head(DT)
##运营商dep_delay年月日arr_delay原点dest air_time
## 1: aa 1498 2014 10 4 1494 ewr DFW 200
## 2: aa 1241 2014 4 15 1223 JFK bos 39
## 3: aa 1071 2014 6 13 1064 ewr DFW 175
## 4: aa 1056 2014 9 12 1115 ewr DFW 198
## 5: aa 1022 2014 6 16 1073 ewr DFW 178
## 6: aa 989 2014 6 11 991 ewr DFW 194
##距离小时sum_delay
## 1: 1372 7 2992
## 2: NA 13 2464
## 3: 1372 10 2135
## 4: 1372 6 2171
## 5: 1372 7 2095
## 6: 1372 11 1980
为了聚合数据,我们提供第三个参数 by 到方括号. Then, in j 我们需要提供聚合函数调用,这样才能真正地聚合数据. The .N 中使用的符号 j 参数对应于每组中所有观察值的数量. 如前所述,聚合可以与行和选择列上的子集相结合.
ans <- DT[,
.(m_arr_delay = mean(arr_delay),
M_dep_delay = mean(dep_delay),
count = .N),
.(载体、月)]
head(ans)
##载波月m_arr_delay m_dep_delay计数
## 1: AA 10 5.541959 7.591497 2705
## 2: AA 4 1.903324 3.987008 2617
## 3: AA 6 8.690067 11.476475 2678
## 4: AA 9 -1.235160 3.307078 2628
## 5: AA 8 4.027474 8.914054 2839
## 6: AA 7 9.159886 11.665953 2802
通常,我们可能需要将行值与其在组上的聚合值进行比较. 在SQL中,我们应用 划分上的聚合: AVG(arr_delay) OVER (PARTITION BY carrier, month).
ans <- DT[,
.(arr_delay, carrierm_mean_arr = mean(arr_delay),
de_delay, carrierm_mean_dep = mean(Dep_delay)),
.(载体、月)]
head(ans)
##运营商月arr_delay carrier erm_mean_arr dep_delay carrier erm_mean_dep
## 1: AA 10 1494 5.541959 1498 7.591497
## 2: AA 10 840 5.541959 848 7.591497
## 3: AA 10 317 5.541959 338 7.591497
## 4: AA 10 292 5.541959 331 7.591497
## 5: AA 10 322 5.541959 304 7.591497
## 6: AA 10 306 5.541959 299 7.591497
如果我们不想用这些聚合来查询数据, 而是把它们放到实际的通过引用更新的表中, 我们可以用 := operator. 这避免了数据集的内存副本, 所以我们不需要将结果赋值给新变量.
DT[,
':= ' (carrierm_mean_arr = mean(arr_delay),
Carrierm_mean_dep = mean(dep_delay)),
.(载体、月)]
head(DT)
##运营商dep_delay年月日arr_delay原点dest air_time
## 1: aa 1498 2014 10 4 1494 ewr DFW 200
## 2: aa 1241 2014 4 15 1223 JFK bos 39
## 3: aa 1071 2014 6 13 1064 ewr DFW 175
## 4: aa 1056 2014 9 12 1115 ewr DFW 198
## 5: aa 1022 2014 6 16 1073 ewr DFW 178
## 6: aa 989 2014 6 11 991 ewr DFW 194
##距离小时sum_delay carrierm_mean_arr carrierm_mean_dep
## 1: 1372 7 2992 5.541959 7.591497
## 2: NA 13 2464 1.903324 3.987008
## 3: 1372 10 2135 8.690067 11.476475
## 4: 1372 6 2171 -1.235160 3.307078
## 5: 1372 7 2095 8.690067 11.476475
## 6: 1372 11 1980 8.690067 11.476475
Base R数据集的连接和合并被认为是一种特殊类型的 subset operation. 在第一个方括号参数中提供要连接的数据集 i. 对于提供给的数据集中的每一行 i,我们匹配我们使用的数据集中的行 [. 如果我们想只保留匹配的行(内连接),然后传递一个额外的参数 nomatch = 0L. We use on 参数指定要在其上连接两个数据集的列.
#创建引用子集
carrierdest <- DT[, .(count=.N), .按载波和dest计数
[1:10]只有10组第一组
# chain ' [...][...’作为子查询
打印(carrierdest)
载波dest count
## 1: aa DFW 5877
## # 2: aa bo 1173
## 3: a ord 4798
## 4: aa sea 298
## 5: 85岁
## 6: aa lax 3449
## 7: aa mia 6058
## 8: aa sfo 1312
## 9: aa = 297
## 10: aa dca 172
#外连接
ans <- carrierdest[DT, on = c("carrier","dest")]
print(ans)
##运营商dest计数dep_delay年月日arr_delay起源
## 1: aa DFW 5877 1498 2014 10 4 1494 ewr
## 2: aa bos 1173 1241 2014 4 15 1223 JFK
## 3: aa DFW 5877 1071 2014 6 13 1064 ewr
## 4: aa DFW 5877 1056 2014 9 12 1115 ewr
## 5: aa DFW 5877 1022 2014 6 16 1073 ewr
## ---
## 253312: wbna na -12 2014 3 9 -21 lga
## 253313: wn MDW na -13 2014 3 10 -18 ewr
## 253314:我的天哪-13 2014 5 17 -30 lga
## 253315: wmmake na -13 2014 6 15 10 lga
## 253316: wca na -13 2014 8 19 -30 lga
## air_time距离小时sum_delay载波平均数arr
## 1: 200 1372 7 2992 5.541959
## 2: 39 NA 13 2464 1.903324
## 3: 175 1372 10 2135 8.690067
## 4: 198 1372 6 2171 -1.235160
## 5: 178 1372 7 2095 8.690067
## ---
## 253312: 115 764 16 -33 6.921642
## 253313: 112 711 20 -31 6.921642
## 253314: 202 1428 17 -43 22.875845
## 253315: 101 738 20 -3 14.888889
## 253316: 63 397 16 -43 7.219670
## carrierm_mean_dep
## 1: 7.591497
## 2: 3.987008
## 3: 11.476475
## 4: 3.307078
## 5: 11.476475
## ---
## 253312: 11.295709
## 253313: 11.295709
## 253314: 30.546453
## 253315: 24.217560
## 253316: 17.038047
#内连接
ans <- DT[carrierdest, # for each row in carrierdest
nomatch = 0L, #只返回两个表中匹配的行
On = c("carrier","dest")] #连接列carrier和dest
print(ans)
##运营商dep_delay年月日arr_delay原点dest air_time
## 1: aa 1498 2014 10 4 1494 ewr DFW 200
## 2: aa 1071 2014 6 13 1064 ewr DFW 175
## 3: aa 1056 2014 9 12 1115 ewr DFW 198
## 4: aa 1022 2014 6 16 1073 ewr DFW 178
## 5: aa 989 2014 6 11 991 ewr DFW 194
## ---
## 23515: aa -8 2014 10 11 -13 JFK dca 53
## 23516: aa -9 2014 5 21 -12 JFK dca 52
## 23517: aa -9 2014 6 5 -6 JFK dca 53
## 23518: aa -9 2014 10 2 -21 JFK dca 51
## 23519: aa -11 2014 5 27 10 JFK dca 55
##距离小时sum_delay carrierm_mean_arr carrierm_mean_deep计数
## 1: 1372 7 2992 5.541959 7.591497 5877
## 2: 1372 10 2135 8.690067 11.476475 5877
## 3: 1372 6 2171 -1.235160 3.307078 5877
## 4: 1372 7 2095 8.690067 11.476475 5877
## 5: 1372 11 1980 8.690067 11.476475 5877
## ---
## 23515: NA 15 -21 5.541959 7.591497 172
## 23516: NA 15 -21 4.150172 8.733665 172
## 23517: NA 15 -15 8.690067 11.476475 172
## 23518: NA 15 -30 5.541959 7.591497 172
## 23519: NA 15 -1 4.150172 8.733665 172
请注意,由于与基R子集的一致性,外部连接在默认情况下是 正确的外. 如果我们在寻找 左外,我们需要交换表,如上面的示例所示. 精确的行为也可以很容易地控制 merge data.table 方法,使用与base R相同的API merge data.frame.
如果我们想简单地查找数据集的列,可以使用 := 运营商 j 加入时的争论. 与通过引用进行子赋值的方式相同,如 更新数据集 节中,我们刚刚通过引用从要连接的数据集添加一个列. 这避免了在内存中复制数据,因此我们不需要将结果赋值给新变量.
DT[载波,#数据].连接表
lkp.Count:= Count, #从' carrier '中查找' Count '列
On = c("carrier","dest")] # join by columns
head(DT)
##运营商dep_delay年月日arr_delay原点dest air_time
## 1: aa 1498 2014 10 4 1494 ewr DFW 200
## 2: aa 1241 2014 4 15 1223 JFK bos 39
## 3: aa 1071 2014 6 13 1064 ewr DFW 175
## 4: aa 1056 2014 9 12 1115 ewr DFW 198
## 5: aa 1022 2014 6 16 1073 ewr DFW 178
## 6: aa 989 2014 6 11 991 ewr DFW 194
##距离小时sum_delay carrierm_mean_arr carrierm_mean_deep LKP.count
## 1: 1372 7 2992 5.541959 7.591497 5877
## 2: NA 13 2464 1.903324 3.987008 1173
## 3: 1372 10 2135 8.690067 11.476475 5877
## 4: 1372 6 2171 -1.235160 3.307078 5877
## 5: 1372 7 2095 8.690067 11.476475 5877
## 6: 1372 11 1980 8.690067 11.476475 5877
For 连接时聚合, use by = .EACHI. 它执行的连接不会实现中间连接结果,而是动态地应用聚合, 提高内存效率.
滚动加入 是为处理有序数据而设计的不常见的特性吗. 它非常适合处理时间数据和一般的时间序列. 它基本上将连接条件下的匹配滚动到下一个匹配值. 来使用它 roll 加入时的争论.
快速重叠连接 通过使用各种重叠操作符,基于周期及其重叠处理连接数据集; any, within, start, end.
A non-equi加入 使用非相等条件连接数据集的特性是当前的 正在开发的.
在探索我们的数据集时, 我们有时可能需要收集有关该主题的技术信息, 以便更好地理解数据的质量.
总结(DT)
# #载体 dep_delay年月
##长度:253316分钟. :-112.00 Min. : 2014分钟. : 1.000
##类:人物第一曲.: -5.00首曲.2014年第1届.: 3.000
##模式:字符中位数:-1.中位数:2014中位数:6.000
平均值:12.47平均:2014平均:5.639
##第三曲.: 11.第三区00.:2014年第三届.: 8.000
## 马克斯. :1498.00 Max. : 2014 Max. :10.000
##
## day arr_delay
## Min. : 1.00 Min. :-112.000长度:253316长度:253316
##第一曲.: 8.00首曲.: -15.000类别:字符类别:字符
中位数:16.00中位数:-4.000模式:字符模式:字符
平均值:15.平均:8.147
##第三曲.:23.第三区00.: 15.000
## Max. :31.00 Max. :1494.000
##
## air_time距离小时sum_delay
## Min. : 20.0 Min. : 80.0 Min. : 0.00 Min. :-224.00
##第一曲.: 86.第1曲.: 529.第1曲.: 9.00首曲.: -19.00
中位数:134.中位数:762.中位数:13.00中位数:-5.00
平均值:156.平均值:950.平均:13.06平均:20.61
##第三曲.:199.第三曲.:1096.第三曲.:17.第三区00.: 23.00
## Max. :706.0 Max. :4963.0 Max. :24.00 Max. :2992.00
NA's:81483
# #载体m_mean_arr carrierm_mean_deep LKP.count
## Min. :-22.403 Min. :-4.500 Min. : 85
##第一曲.: 2.第676区.: 7.第815区.:3449
中位数:6.中位数:11.中位数:5877
平均值:8.平均:12.平均:4654
##第三曲.: 11.三区554号.:17.第三区564.:6058
## Max. : 86.182 Max. :52.864 Max. :6058
NA's:229797
我们可以检查 数据的唯一性 by using uniqueN 函数并将其应用于每一列. Object .SD 在下面的查询中对应于 S的子集 Data.table:
DT(拉普兰人(.SD, uniqueN)]
##运营商dep_delay年月日arr_delay原点dest air_time
## 1: 14 570 1 10 31 616 3 109 509
##距离小时sum_delay carrierm_mean_arr carrierm_mean_deep LKP.count
## 1: 152 25 1021 134 134 11
计算未知值(NA in R, and NULL 在SQL中),我们为每个列提供应用于每个列的所需函数.
DT(拉普兰人(.SD,函数(x)和(是.na(x))/.N)]
##运营商dep_delay年月日arr_delay原点dest air_time
## 1: 0 0 0 0 0 0 0 0 0
##距离小时sum_delay carrierm_mean_arr carrierm_mean_deep LKP.count
## 1: 0.3216654 0 0 0 0 0.9071555
快速导出表格数据到 CSV format 也由 data.table package.
tmp.csv <- tempfile(fileext=".csv")
写入文件(DT, tmp.csv)
#预览导出数据
猫(系统(粘贴(“3”,tmp.csv), intern=TRUE), sep="\n")
# #载体,dep_delay,year,month,day,arr_delay,origin,dest,air_time,distance,hour,sum_delay,carrierm_mean_arr,carrierm_mean_dep,lkp.count
# # AA、1498、2014、10、4、1494年,英文文宣写作研习营,DFW, 200年,1372年,7,2992,5.54195933456561,7.59149722735674,5877
4 # # AA, 1241年,2014年,15日,1223年,肯尼迪,BOS, 39岁,13日,2464年,1.90332441727168,3.98700802445548,1173
在写这篇文章的时候, fwrite 函数尚未发布到CRAN存储库. 要使用它,我们需要 install data.table 开发版,否则我们可以用R为底 write.csv 函数,但不要期望它很快.
有很多可用的资源. 除了每个功能可用的手册, 也有包装小插图, 哪些是围绕特定主题的教程. 这些可以在 开始 page. 此外, 演讲 该页列出了30多个材料(幻灯片,视频等).) from data.table 全球演讲. Also, 多年来,社区的支持不断增加, 最近在Stack Overflow上遇到了第4000个问题 data.table 标签,仍然有很高的比率(91.9%)的回答问题. 下面的图表显示了……的数量 data.table 随着时间的推移,在Stack Overflow上标记问题.
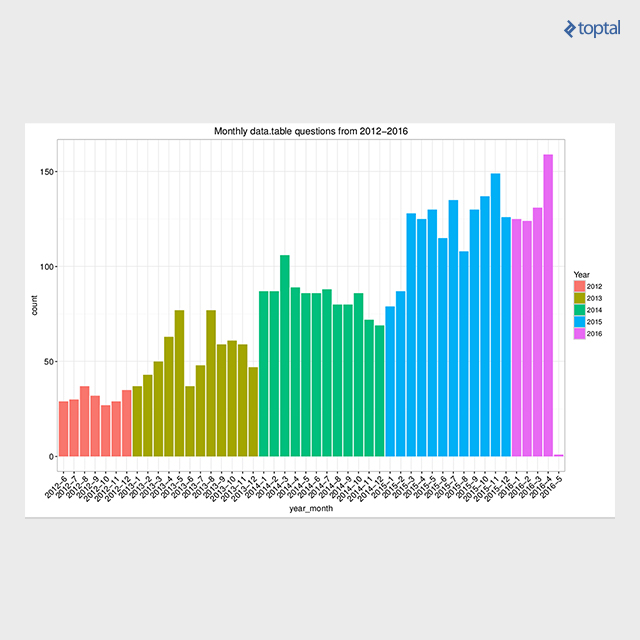
方法在R中进行有效的表格数据转换 data.table package. 可以通过寻找可重复的基准来检查性能的实际数字. 我发表了一篇关于 data.table 为R语言提供的排名前50位的StackOverflow问题的解决方案 用数据有效地解决常见的R问题.table,在那里你可以找到很多图表和可复制的代码. 这个包 data.table 对其分组操作使用快速基数排序的本机实现, 和二分查找快速子集/连接. 这个基数的排序已经从版本中纳入到基数R中 3.3.0. 另外, 该算法最近在H2O机器学习平台上实现,并在H2O集群上并行化, 在10B × 10B行上实现高效的大连接.
世界级的文章,每周发一次.
世界级的文章,每周发一次.
